Node.js 운영 입문: nvm·pm2·docker를 “역할”로만 정리해보자
Node.js 서비스 운영을 처음 접하면 용어가 한 번에 몰려옵니다. nvm은 버전, pm2는 프로세스, docker는 패키징/격리… 오늘은 “개념을 역할로 쪼개서” 깔끔하게 정리해 보겠습니다.
① nvm·pm2·docker의 역할을 분리해서 이해하고,
② PM2 방식과 Docker 방식의 운영 흐름을 비교한 뒤,
③ 내 환경(단일 서버 / 여러 서비스 / 배포 방식)에 맞게 선택할 수 있게 만드는 것. — 개발자용 “정답”이 아니라, 운영자 입장에서의 “선택 기준”을 만들어요.
제약: 서버 수(1대/여러 대), 배포 빈도, 팀 역량, 시간
선택: PM2(프로세스 관리) vs Docker(패키징+격리) vs (확장) K8s(오케스트레이션)
다음 행동: 가장 작은 단위로 먼저 성공(1개 서비스) → 표준화(템플릿화)
런타임(Node) / 버전(nvm) / 프로세스(pm2) / 패키징(docker) / 대규모 운영(k8s)
1. Node.js, nvm, pm2는 각각 무슨 역할인가요?
한 장 표로 역할 정리
| 이름 | 한 줄 정의 | 주로 해결하는 문제 | 키워드 |
|---|---|---|---|
| Node.js | 서버에서 JS를 실행하는 런타임 | “JS로 서버 프로그램을 돌리고 싶다” | 런타임, V8, 이벤트 루프 |
| nvm | Node 버전 설치/전환 도구 | “서비스마다 필요한 Node 버전이 다르다” | 버전 고정(.nvmrc), LTS, 전환 |
| pm2 | Node 프로세스 운영/관리 도구 | “죽으면 재시작, 로그 보기, 무중단 배포” | start/reload, logs, startup, cluster |
| Docker | 앱+실행환경을 이미지로 패키징해 격리 실행 | “서버마다 환경이 달라서 배포가 흔들린다” | image/container, 이식성, 재현성 |
그래서 컨테이너는 보통 더 가볍고 빠르게 뜨고, 운영 표준화를 만들기 쉽습니다.
2. PM2를 활용한 프로세스 관리 방식
PM2 방식은 간단히 말해 서버에 Node를 설치해 두고, 앱은 pm2로 띄워서 살려두는 운영입니다. “서버 한 대에 서비스 몇 개” 정도면 정말 빠르게 안정화하기 좋습니다.
2-1) PM2 정의(무슨 일을 해주나요?)
- 프로세스 생존: 앱이 죽으면 자동 재시작
- 무중단 reload: 코드 업데이트 시 끊김을 줄이면서 재시작
- 로그 관리: 로그 파일/실시간 스트림 확인
- 클러스터: CPU 코어를 활용해 여러 인스턴스로 띄우기(선택)
2-2) 설치(요약)
(1) nvm 설치 — 리눅스/맥 기준
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/master/install.sh | bash
# 설치 후 터미널 재시작 또는 아래 실행
source ~/.bashrc(2) Node 설치 (예: 최신 LTS)
nvm install --lts
nvm use --lts
node -v
npm -v(3) PM2 설치
npm i -g pm2@latest
pm2 -v2-3) 사용(필수 명령어만 “운영자 시선”으로)
# 1) 앱 실행(등록)
pm2 start app.js --name my-api
# 2) 목록 확인
pm2 ls
# 3) 로그 보기(실시간)
pm2 logs my-api
# 4) 재시작 / 무중단 reload(가능한 경우)
pm2 restart my-api
pm2 reload my-api
# 5) 중지/삭제
pm2 stop my-api
pm2 delete my-api2-4) ecosystem.config.js (운영에서 가장 많이 쓰는 “한 파일 운영”)
여러 옵션을 CLI에 매번 적는 대신, 설정을 파일로 고정해 두면 실수가 확 줄어듭니다.
module.exports = {
apps: [
{
name: "my-api",
script: "server.js",
instances: 2, // "max" 로 두면 CPU 코어 수만큼
exec_mode: "cluster", // 단일이면 "fork"
env: {
NODE_ENV: "production",
PORT: 3000
}
}
]
};실행
pm2 start ecosystem.config.js --env production2-5) 재부팅 후에도 자동으로 살아나게(매우 중요)
서버 재부팅/장애 이후에 자동으로 앱이 올라오게 하려면 “startup + save”를 설정합니다.
# 1) 부팅 자동 시작 스크립트 생성(시스템에 맞게 자동 감지)
pm2 startup
# 2) 현재 프로세스 목록 저장(다음 부팅 때 resurrect)
pm2 save3. Docker를 활용한 Node.js 관리(패키징/격리 운영)
Docker 방식은 Node 버전/의존성/앱을 이미지(Image)로 묶어서 컨테이너(Container)로 실행합니다. “서버마다 환경이 달라서 배포가 흔들리는 문제”를 크게 줄여줍니다.
3-1) Docker 정의(운영자 눈높이)
- Image: 앱 실행에 필요한 모든 것을 “압축해 둔 실행 패키지”
- Container: 그 이미지를 실제로 실행한 “프로세스(격리된 실행 인스턴스)”
- 장점: 같은 이미지를 어디서 실행하든 결과가 비슷해져서 배포가 안정적
Docker는 “환경까지 포함해 똑같이 실행되게 하는 패키징”에 강합니다.
3-2) Docker 설치(요약 · Ubuntu 기준)
설치는 공식 문서가 가장 안전합니다. 아래는 “흐름만” 잡는 요약이고, 자세한 명령은 참고 링크를 따라가시면 됩니다.
# (요약) Ubuntu에서 Docker Engine 설치 흐름
# 1) 이전/충돌 패키지 제거
sudo apt remove -y docker.io docker-compose docker-compose-v2 docker-doc podman-docker containerd runc || true
# 2) 저장소 준비(필수 패키지)
sudo apt update
sudo apt install -y ca-certificates curl gnupg
# 3) Docker 공식 저장소 등록 후 docker-ce 설치 (공식 문서 참고)
# 4) 설치 확인
docker version
docker run --rm hello-world3-3) 사용(필수 명령어: build/run/logs)
(1) Dockerfile 예시 — “Node 앱 하나”를 이미지로 만드는 최소 형태
# Dockerfile
FROM node:lts-alpine
WORKDIR /app
COPY package*.json ./
RUN npm ci --omit=dev
COPY . .
EXPOSE 3000
CMD ["node", "server.js"](2) 이미지 빌드
docker build -t my-api:1.0 .(3) 컨테이너 실행 — 재시작 정책까지 같이
docker run -d --name my-api \
-p 3000:3000 \
--restart unless-stopped \
-e NODE_ENV=production \
my-api:1.0(4) 운영 명령어
# 상태/목록
docker ps
docker stats
# 로그
docker logs -f my-api
# 컨테이너 안으로 들어가기(필요할 때만)
docker exec -it my-api sh
# 중지/삭제
docker stop my-api
docker rm my-api--restart)으로 컨테이너를 살려둘 수 있어요. 그래서 공식 문서에서도 “프로세스 매니저로 컨테이너를 띄우기보다 restart policy를 쓰는 편”을 권장합니다.4. 두 방식의 장단점 상세 비교 및 프로세스 흐름도 비교
4-1) 한눈에 보는 장단점 비교표
| 비교 항목 | PM2 방식(호스트에서 Node 직접 운영) | Docker 방식(이미지/컨테이너로 운영) |
|---|---|---|
| 설치/진입 난이도 | 빠르게 시작 가능(서버에 Node+nvm+pm2) | Docker 개념(이미지/컨테이너/네트워크) 학습이 필요 |
| 환경 재현성 | 서버 상태(설치된 패키지/버전)에 영향을 받기 쉬움 | 이미지에 환경이 고정되어 재현성이 높음 |
| 버전 관리 | nvm으로 가능하지만 운영 표준이 없으면 흔들림 | 이미지 태그로 버전 고정/롤백이 쉬움 |
| 장애 복구 | pm2 재시작/부팅 자동화로 커버 | restart policy + (선택) 헬스체크/오케스트레이션으로 커버 |
| 리소스 오버헤드 | 가벼움(호스트에서 바로 실행) | 컨테이너 레이어 오버헤드가 약간 있지만 보통은 충분히 가벼운 편 |
| 격리/충돌 방지 | 서비스 간 충돌(라이브러리/환경)이 생기면 골치 | 컨테이너로 분리되어 충돌 가능성이 낮아짐 |
| 여러 서비스 운영 | 서비스가 늘수록 “서버 수제 관리”가 되기 쉬움 | Compose/K8s로 확장 시 운영 표준화가 쉬움 |
| 운영자 체감 | “서버 안에서 직접 만지며” 빠르게 고칠 수 있음 | “이미지 빌드/배포 파이프라인”이 잡히면 안정적 |
4-2) 프로세스 흐름도 비교



4-3) 어떤 걸 고르면 좋을까요? (운영자 기준 추천)
- 서버 1~2대, 서비스도 많지 않다
- “지금 당장” 빠르게 올려야 한다
- 서버에서 직접 디버깅/수정하는 일이 잦다
- 서비스가 늘어나면서 환경이 꼬이기 시작했다
- 배포를 표준화하고, 롤백을 쉽게 만들고 싶다
- 나중에 Compose/K8s로 확장할 가능성이 있다
5. Docker Compose로 “2~3개 서비스” 묶어 운영하는 템플릿
Docker를 “서비스 2~3개 이상” 운영하기 시작하면, docker run을 여러 줄로 관리하는 순간부터 실수가 늘어납니다. 이때 Compose로 한 파일(compose.yaml)에 묶어두면 운영이 훨씬 편해져요.
- nginx: 외부 트래픽을 받고 API/웹으로 라우팅하는 Reverse Proxy
- api: Node.js 서비스(컨테이너)
- redis (선택): 캐시/세션/큐 같은 “외부 의존 서비스” 예시
5-1) 권장 폴더 구조
/opt/my-stack/
├─ compose.yaml
├─ nginx/
│ └─ conf.d/
│ └─ app.conf
└─ api/
├─ Dockerfile
├─ package.json
└─ server.js5-2) compose.yaml 예시(nginx + api + redis)
services:
nginx:
image: nginx:stable-alpine
container_name: my-nginx
ports:
- "80:80"
volumes:
- ./nginx/conf.d:/etc/nginx/conf.d:ro
depends_on:
- api
restart: unless-stopped
networks:
- appnet
api:
build:
context: ./api
dockerfile: Dockerfile
container_name: my-api
environment:
NODE_ENV: "production"
PORT: "3000"
# 예: 외부 연동값은 여기서 주입
REDIS_URL: "redis://redis:6379"
expose:
- "3000"
restart: unless-stopped
healthcheck:
test: ["CMD-SHELL", "wget -qO- http://localhost:3000/health || exit 1"]
interval: 10s
timeout: 2s
retries: 5
networks:
- appnet
redis:
image: redis:7-alpine
container_name: my-redis
restart: unless-stopped
networks:
- appnet
networks:
appnet:
driver: bridge# 올라가기/내리기
docker compose up -d
docker compose down
# 상태/로그
docker compose ps
docker compose logs -f --tail=200
# 설정 변경 후 (이미지 재빌드 포함)
docker compose up -d --build6. Nginx Reverse Proxy + (간단) Health Check + 로그 표준화
실무에서는 Node 앱을 외부에 바로 노출하기보다, 보통 Nginx 같은 Reverse Proxy 앞단에서 SSL/보안 헤더/로그/라우팅을 표준화해 둡니다.
6-1) Nginx 라우팅 기본 템플릿(HTTP)
아래 예시는 /는 정적 웹(있다면), /api는 Node API로 보내는 구조입니다. (정적 웹이 없으면 location / 블록은 지워도 됩니다.)
# ./nginx/conf.d/app.conf
upstream api_upstream {
server my-api:3000 max_fails=2 fail_timeout=10s;
# 컨테이너 여러 개면 server를 여러 줄로 추가
# server my-api2:3000 max_fails=2 fail_timeout=10s;
}
log_format json_combined escape=json
'{'
'"time":"$time_iso8601",'
'"remote_addr":"$remote_addr",'
'"method":"$request_method",'
'"uri":"$request_uri",'
'"status":$status,'
'"bytes":$body_bytes_sent,'
'"ref":"$http_referer",'
'"ua":"$http_user_agent",'
'"rt":$request_time,'
'"urt":"$upstream_response_time",'
'"uaddr":"$upstream_addr"'
'}';
server {
listen 80;
server_name _;
access_log /var/log/nginx/access.log json_combined;
error_log /var/log/nginx/error.log warn;
# (옵션) 프록시 기본 헤더
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# (간단) 헬스 엔드포인트 — Nginx 자체 상태 확인용
location = /_nginx_health {
return 200 "ok\n";
add_header Content-Type text/plain;
}
# API 라우팅
location /api/ {
proxy_pass http://api_upstream/;
proxy_http_version 1.1;
# 장애 시 다음 업스트림으로 넘길지(간단한 failover)
proxy_next_upstream error timeout http_502 http_503 http_504;
}
# (옵션) 정적 웹 라우팅 예시
# location / {
# root /usr/share/nginx/html;
# try_files $uri $uri/ =404;
# }
}- 컨테이너/앱 헬스:
/health같은 API endpoint + Docker healthcheck로 “앱이 정상인지” 확인 - Nginx 헬스:
/_nginx_health처럼 “프록시가 살아있는지” 확인 - 업스트림 실패 처리:
max_fails,fail_timeout,proxy_next_upstream으로 “죽은 서버를 잠깐 피하는” 수준의 처리를 구성
6-2) 로그 표준화(운영자가 편해지는 포인트)
- Nginx access log는 JSON 형태로: SIEM/ELK로 넘길 때 파싱이 훨씬 쉬워요.
- 앱 로그는 “표준 출력(stdout/stderr)”로: Docker/Compose가 모아주게 두면 운영이 단순해집니다.
- 로그 로테이션은 필수: 용량이 커지면 장애로 이어집니다.
(1) Docker/Compose 로그(기본)
# 컨테이너 로그 보기
docker logs -f my-api
# Compose로 묶인 로그 보기
docker compose logs -f --tail=200(2) PM2 로그 로테이션(서버 직접 운영 시)
# pm2-logrotate 설치
pm2 install pm2-logrotate
# 현재 로그 위치 확인(기본: ~/.pm2/logs)
pm2 logs
pm2 flush7. PM2 / Docker 운영 체크리스트(각 20개)
아래 체크리스트는 “사고가 났을 때”보다 “사고가 나기 전에” 도움이 되는 항목들입니다. 그대로 복사해서 팀 위키/런북으로 써도 괜찮아요.
7-1) PM2 운영 체크리스트(20)
| # | 점검 항목 | 왜 중요한가요? |
|---|---|---|
| 1 | Node 버전 고정(.nvmrc / 문서화) | 서버별/배포 시 버전 차이로 장애가 생깁니다. |
| 2 | npm ci 사용(가능하면) | 의존성 설치 결과가 더 재현 가능해집니다. |
| 3 | ecosystem.config.js로 옵션 표준화 | CLI 옵션 누락/실수를 줄입니다. |
| 4 | pm2 startup + pm2 save 적용 | 재부팅 후 자동 복구가 됩니다. |
| 5 | 로그 경로/용량 점검(~/.pm2/logs) | 디스크 풀은 대표적인 장애 원인입니다. |
| 6 | pm2-logrotate 적용 | 로그 로테이션 없으면 어느 날 갑자기 터집니다. |
| 7 | 환경변수 관리(파일/시크릿 분리) | 운영/개발 설정이 섞이면 사고가 납니다. |
| 8 | PORT 충돌 방지(서비스별 포트 정책) | 한 서버 다중 서비스 운영에서 가장 흔합니다. |
| 9 | reverse proxy(Nginx) 앞단화 | SSL/보안헤더/로그/라우팅 표준화가 됩니다. |
| 10 | /health 엔드포인트 제공 | 헬스체크/모니터링/자동복구의 출발점입니다. |
| 11 | 무중단 reload 전략 확보 | 업데이트 때 끊김을 줄입니다. |
| 12 | 클러스터 모드 사용 시 세션/캐시 고려 | 인스턴스가 늘면 상태 공유 문제가 생깁니다. |
| 13 | 메모리/CPU 상한 모니터링 | 누수/폭주를 조기에 발견합니다. |
| 14 | PM2 프로세스 이름 규칙 | 운영자가 “어떤 서비스인지” 즉시 알아야 합니다. |
| 15 | 릴리즈/롤백 절차 문서화 | 새벽 장애 때 ‘손’이 자동으로 움직이게 합니다. |
| 16 | systemd와 역할 분리(누가 무엇을 재시작?) | 중복 관리하면 오히려 예측이 깨집니다. |
| 17 | 방화벽/보안그룹 규칙 점검 | 포트 오픈 실수로 외부 노출이 생깁니다. |
| 18 | 백업/설정 백업(nginx conf, env) | 복구 속도를 결정합니다. |
| 19 | 시간/타임존 고정 | 로그 분석/배치 시간 관련 장애를 줄입니다. |
| 20 | 운영자용 원라인 점검 명령 세트 | “지금 상태가 뭔지” 30초 안에 확인 가능합니다. |
7-2) Docker/Compose 운영 체크리스트(20)
| # | 점검 항목 | 왜 중요한가요? |
|---|---|---|
| 1 | 이미지 태그 버전 고정(immutable) | latest로 운영하면 롤백이 어렵습니다. |
| 2 | compose.yaml로 표준화 | run 명령 난립을 막습니다. |
| 3 | restart 정책 설정 | 컨테이너가 죽었을 때 자동 복구됩니다. |
| 4 | healthcheck 설정 | “살아있음”을 기계가 판단할 수 있습니다. |
| 5 | 로그 전략 결정(stdout 기반 추천) | 수집/분석 표준화가 쉬워집니다. |
| 6 | 컨테이너 이름/서비스명 규칙 | 운영 시 탐색 비용이 줄어듭니다. |
| 7 | 네트워크 분리(appnet 등) | 불필요한 노출을 줄입니다. |
| 8 | 포트 공개 최소화(expose vs ports) | 외부 노출 사고를 방지합니다. |
| 9 | 볼륨/데이터 영속성 설계 | 컨테이너 재생성 시 데이터 유실 방지 |
| 10 | 시크릿/환경변수 분리 | 민감정보 유출 방지 |
| 11 | 리소스 제한(CPU/Mem) | 한 서비스 폭주가 전체를 망치지 않게 |
| 12 | 베이스 이미지 보안 업데이트 | 취약점 대응 |
| 13 | 이미지 빌드 캐시 전략 | 배포 시간을 줄입니다. |
| 14 | 롤백 절차(이전 태그로 up) | 장애 때 되돌리기가 쉬워야 합니다. |
| 15 | Nginx 앞단 표준화 | SSL/보안헤더/로그/라우팅 통합 |
| 16 | 업스트림 실패 처리(max_fails/fail_timeout) | 죽은 인스턴스로 가는 트래픽을 줄입니다. |
| 17 | 이미지 스캔/취약점 점검 | 운영 환경 보안 기본기 |
| 18 | 권한 최소화(루트 실행 피하기) | 침해 시 피해 범위를 줄입니다. |
| 19 | 백업/복구(볼륨/설정) | 복구 속도가 품질입니다. |
| 20 | 운영자 원라인 점검 세트 | ps/logs/exec가 손에 익어야 합니다. |
# PM2
pm2 ls && pm2 logs --lines 50
# Docker/Compose
docker ps && docker compose ps
docker compose logs -f --tail=100부록. 실전 트러블슈팅: docker-compose 설치 이후 기존 docker 컨테이너가 내려간 이유
docker-compose 자체가 컨테이너를 “죽인” 게 아니라, docker-compose 설치 과정에서 Docker Engine(containerd 포함)가 업그레이드되면서 daemon이 재시작됐고, 그 여파로 일부 컨테이너가 내려간 채로 남은 케이스입니다.
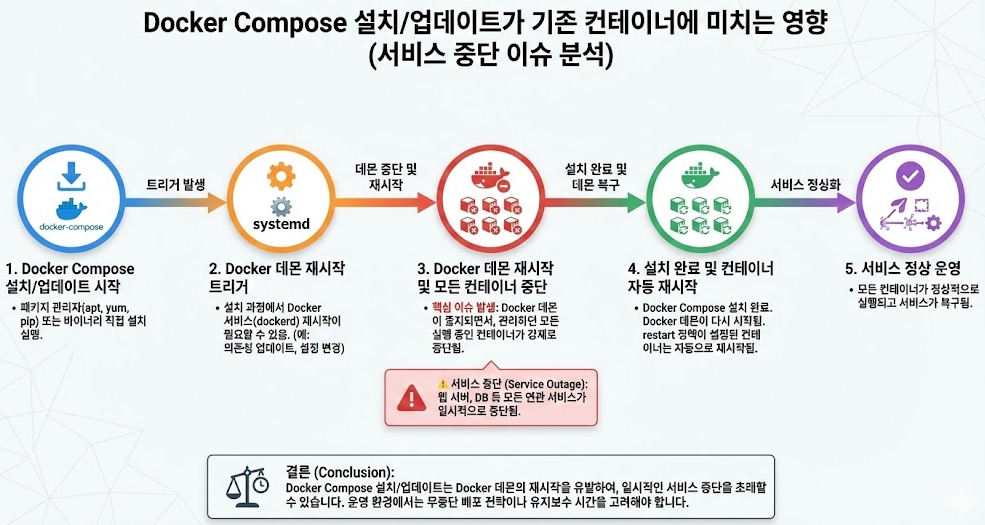
A) 왜 이런 일이 생기나 (핵심 원리)
- docker-compose(v1)는 서비스 오케스트레이션 툴(클라이언트)이고, 일반적으로는 “compose up/down”으로 컨테이너를 제어합니다.
- 그런데 운영 서버에서 apt로 docker-compose를 설치하면, 환경/리포지토리/의존성 상태에 따라 docker-ce, docker-ce-cli, containerd.io가 같이 업그레이드될 수 있습니다.
- Docker/Containerd 패키지 업그레이드 과정에서 systemd가 docker/containerd를 재시작할 수 있고, 이때 기존 컨테이너들이 SIGTERM을 받습니다.
- 재시작 정책(restart policy)이 없거나, compose로 다시 올려주지 않으면 Exited 상태로 남아 포트가 “안 열려 보이는” 상황이 발생합니다. (ExitCode=143은 SIGTERM으로 종료된 케이스가 흔합니다)
B) Docker vs Docker Compose(운영 관점) & v1/v2 차이(오늘 장애 포인트)
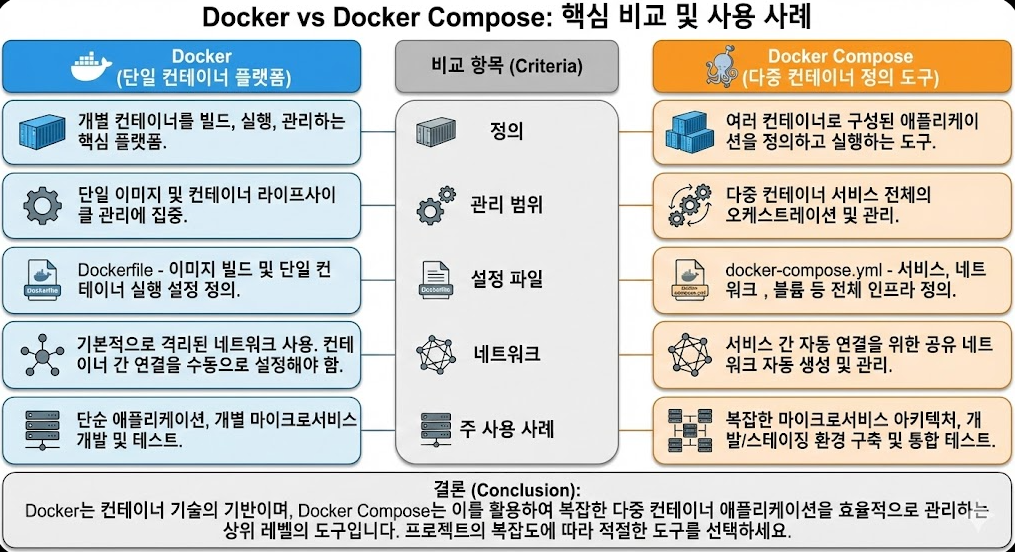
운영에서 중요한 건 “무엇으로 올렸는지(단일 docker / compose)”와 “재시작 정책이 표준화돼 있는지”입니다.
- docker-compose(하이픈)는 전통적인 Compose v1(Python 기반) 명령입니다.
- docker compose(공백)는 Docker CLI 플러그인 형태의 Compose v2 명령입니다.
- 운영 서버에선 “어느 쪽을 표준으로 쓸지”를 문서에 명확히 고정하는 게 좋습니다(혼재하면 장애 시 커맨드가 헷갈립니다).
C) 오늘 같은 상황에서 “원인/영향”을 빠르게 확인하는 명령어 세트
본문에서 기본 명령들은 이미 다뤘기 때문에, 여기서는 장애 상황에서 증거를 남기는 순서 위주로 정리합니다.
# 0) 포트 레벨(리버스/프록시가 있으면 같이 확인)
ss -lntp | egrep ':8200|:8300|:8301'
# 1) “포트 = 컨테이너” 빠른 매핑
docker ps --format 'table {.Names} {.Image} {.Status} {.Ports}' | egrep '8200|8300|8301'
# 2) 포트가 안 보이면: Exited/Created 찾기
docker ps -a --format 'table {.ID} {.Names} {.Image} {.Status} {.Ports}' | egrep '8200|Exited|Created'
# 3) “왜 내려갔나” 1차: 로그/종료코드
docker logs --tail 200 wiseapi-container
docker inspect -f '{.State.FinishedAt} Exit={.State.ExitCode} OOM={.State.OOMKilled} Err={.State.Error}' wiseapi-container
# 4) “누가 먼저 죽였나” 2차: events (시간대 지정)
docker events --since '2026-01-19T11:00:00' --until '2026-01-19T11:15:00' --filter container=wiseapi-container
# 5) docker daemon이 재시작됐는지(시간대 지정)
journalctl -u docker -S '2026-01-19 11:05:00' -U '2026-01-19 11:10:00' --no-pager
journalctl -u containerd -S '2026-01-19 11:05:00' -U '2026-01-19 11:10:00' --no-pager# 패키지 설치/업그레이드 내역(가장 신뢰도 높음)
# /var/log/dpkg.log
2026-01-19 11:06:21 upgrade docker-ce-cli ... 27.x → 29.x
2026-01-19 11:06:22 upgrade containerd.io ... 1.x → 2.x
2026-01-19 11:06:23 upgrade docker-ce ... 27.x → 29.x
2026-01-19 11:06:25 install docker-compose ...
# /var/log/apt/history.log
Commandline: apt install docker-compose
Upgrade: containerd.io, docker-ce-cli, docker-ceD) “누가/어디서/무슨 명령을 쳤나” 추적 팁(기본 로그 기준)
운영 서버 기본 로그만으로는 “sudo로 실행한 명령(tty/시간/경로)”는 잘 남지만, 그 tty가 어떤 원격 IP 세션인지는 로그 레벨/감사(audit) 설정에 따라 달라집니다. 최소한 아래 조합으로 “누가 무엇을 했는지”는 충분히 좁힐 수 있습니다.
# 1) SSH 접속 IP/시간 (auth.log)
grep -aE 'sshd.*Accepted|sshd.*session opened' /var/log/auth.log | tail -n 200
# 2) sudo로 실행한 명령/TTY/PWD (journalctl)
journalctl -S '2026-01-19 10:30:00' -U '2026-01-19 12:00:00' --no-pager | grep -a 'sudo\[' | egrep 'docker|docker-compose|apt install docker-compose'
# 3) bash history(동일 세션에서 확인)
export HISTTIMEFORMAT='%F %T '
history | tail -n 200
# (보강) 더 정확한 “원격 IP ↔ TTY ↔ 실행 커맨드” 매핑이 필요하면
# auditd(예: ausearch), sshd LogLevel VERBOSE 등 “감사/로그 강화”를 고려합니다.E) 운영 서버에 docker-compose(또는 docker compose) 설치/업그레이드 시 유의점(재발 방지 체크리스트)
- 패키지 업그레이드가 같이 묶이지 않는지 미리 확인합니다:
apt-get -s install docker-compose(dry-run)로 업그레이드 대상 체크 - 운영 시간대 설치/업그레이드 금지: Docker Engine/containerd 업그레이드는 daemon 재시작 가능성이 있습니다(=컨테이너 영향)
- restart policy 표준화: “일반 docker 컨테이너”는 특히
--restart unless-stopped를 기본값으로 고려합니다 - Compose로 올린 서비스는 Compose로 관리:
docker compose up -d로 재기동, 상태/로그는docker compose ps/logs중심 - daemon 재시작 이벤트 모니터링: 장애 분석에서
journalctl -u docker,docker events는 거의 “증거” 수준입니다 - 버전 정책: 가능하면 Docker 문서 권장 방식(Compose v2 플러그인) 기준으로 표준화하고, 배포 문서에 “우리 환경은 v1/v2 중 무엇인지”를 명시합니다
# 1) docker daemon 최근 재시작?
journalctl -u docker -n 200 --no-pager | tail
# 2) Exited 컨테이너 한 번에 보기
docker ps -a --filter status=exited
# 3) 재시작 정책 빠진 컨테이너 찾기(운영 표준화 포인트)
docker ps -a --format '{.Names}' | while read c; do echo -n "$c => "; docker inspect -f '{.HostConfig.RestartPolicy.Name}' "$c"; done참고 자료
- Node.js 공식 문서(“JavaScript runtime built on V8”): nodejs.org
- Node.js 소개(런타임 개요): nodejs.org
- nvm 공식 GitHub(설치/사용): github.com/nvm-sh/nvm
- PM2 Overview: pm2.io
- PM2 Quick Start(설치/기본 명령): pm2.keymetrics.io
- PM2 Process Management(기본 start/ls/delete): pm2.io
- PM2 Startup(부팅 자동 시작): pm2.keymetrics.io
- PM2 Log Management(로그 위치/조회): pm2.keymetrics.io
- Docker Engine 설치(Ubuntu): docs.docker.com
- Docker: 컨테이너란? (VM 비교 포함): docs.docker.com
- Docker: 컨테이너 자동 시작/재시작 정책: docs.docker.com
- Kubernetes 개요(컨테이너 오케스트레이션): kubernetes.io
- (심화) Namespaces/Cgroups 개념: nginx.org
- Docker Compose 파일 포맷(Compose Specification): docs.docker.com
- Compose services 정의(services 블록): docs.docker.com
- Compose startup order(depends_on): docs.docker.com
- Docker restart policy 권장(프로세스 매니저 대신): docs.docker.com
- Nginx upstream(max_fails/fail_timeout): nginx.org
- Nginx load balancing 개요(max_fails 설명 포함): nginx.org
'Tech Note > 개요 (개발)' 카테고리의 다른 글
| 5. WAS의 종류와 역할, 운영 툴 총 정리 (1) | 2026.01.16 |
|---|---|
| 4. 내부 마이크로서비스와 웹 프레임워크(Flask·Django·FastAPI) (1) | 2026.01.15 |
| 3. 3‑Tier(Web–WAS–DB)로 보는 프론트·백·DB·프레임워크 (1) | 2026.01.10 |
| 1. 초보 개발자들의 학습 순서 (1) | 2026.01.04 |